FRAMEWORK
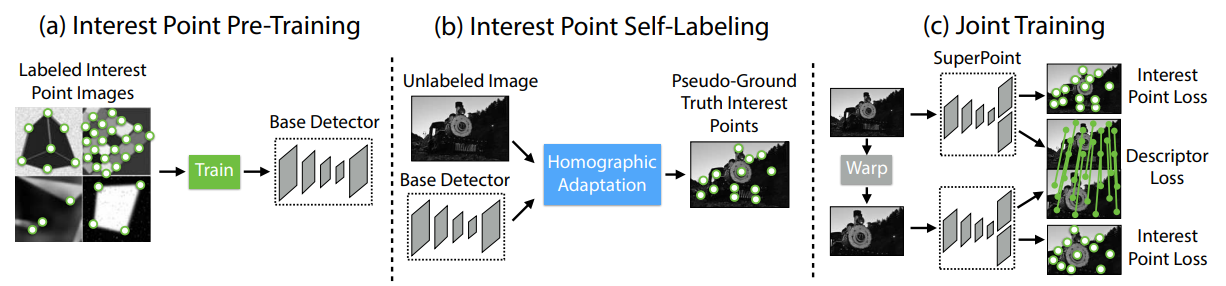
MAINLY THREE PARTS(pic above):
- Interest Point Pre-Training
- use synthetic dataset(easy to get corner pts, e.g. L/Y/T junctions…)
-
train base detector(what is the detector‘s arch?)
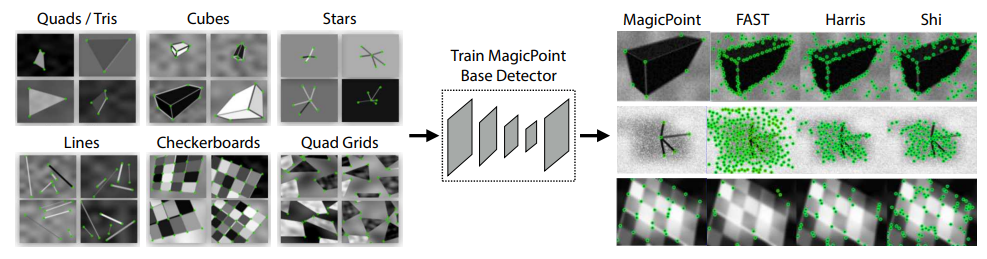
- transfer to real img(next steps)
- Interest Point Self-Labeling(sample random homography,generate pseudo-GT)
- use base detector to inference(init interest pts in real img)
- use homographic adaption(detail?)
- Joint Training(interest pts and descriptor)
- loss
- network arch
METHOD DETAIL
NETWORK DESIGN
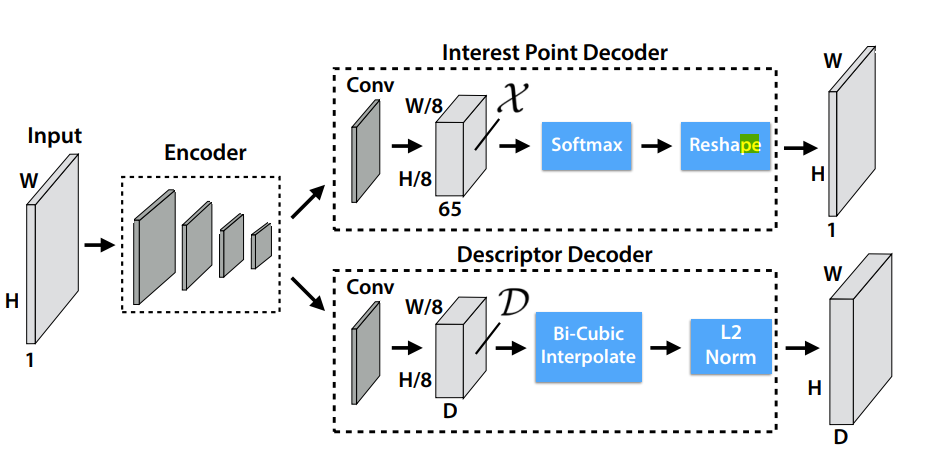
- encoder-decoder architecture
- shared encoder(advantages?)
- two heads
- Shared Encoder
- VGG-styled
- pixel cells
three 2×2 non-overlapping max pooling operations in the encoder result in 8 × 8 pixel cells
- Interest Point Decoder
- NO upsampling layers(high computation & unwanted checkerboard artifacts)
- designed the interest point detection head(with an explicit decoder)
This decoder has no parameters, and is known as “sub-pixel convolution” or “depth to space” in TensorFlow or “pixel shuffle” in PyTorch
- Descriptor Decoder
- similar to UCN(Universal Correspondence Network)
- perform bicubic interpolation of the descriptor and then L2-normalizes(fixed)
LOSS FUNC
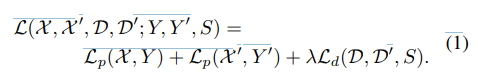
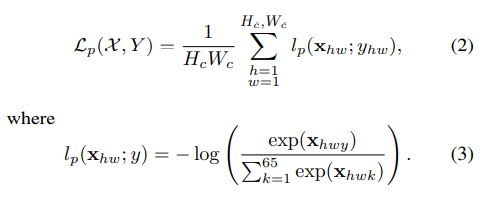
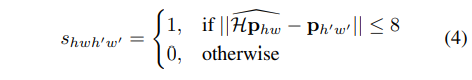
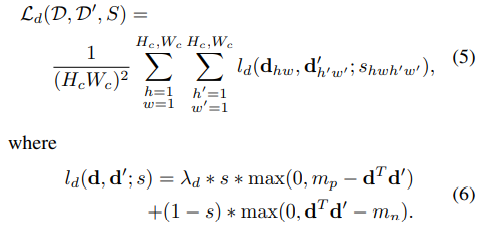
HOMOGRAPHY
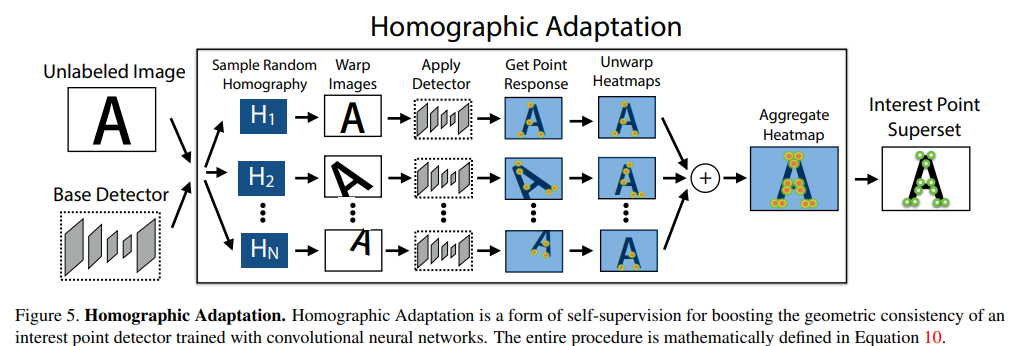
-
formulation
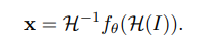
- $I$: input image
- $x$: resulting interest points
- $f_\theta$: network
- $\mathcal{H}$: homography
-
improved super-point detector
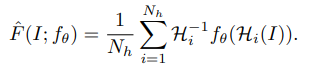
-
choosing homographies
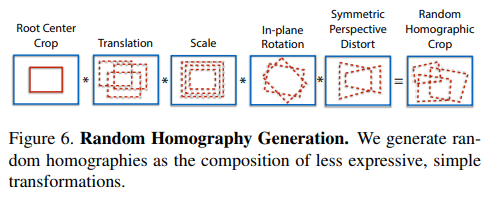
-
Iterative Homographic Adaptation

RESOURCE
rpautrat/SuperPoint: Efficient neural feature detector and descriptor (github.com)
腾讯优图荣获CVPR2021 Image Matching Workshop双赛道冠亚军 (qq.com)