🔍 一、整体架构设计
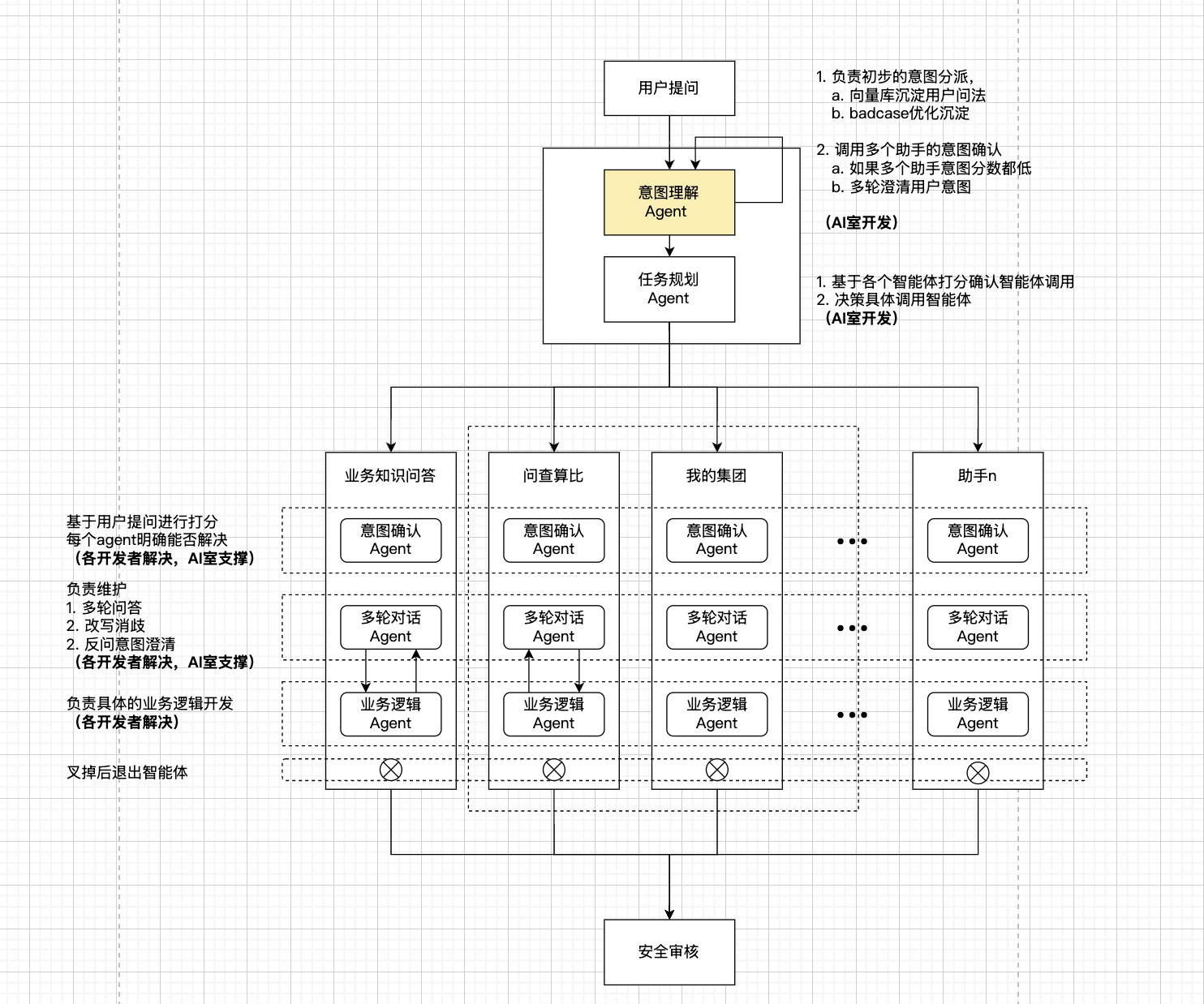
💡 我们采用分层模块化的设计理念,构建了一个灵活可扩展的多智能体系统。这种设计不仅确保了系统的高可用性,也为未来的功能扩展提供了良好的基础。
基于多智能体的架构设计采用分层模块化方案,主要包含以下核心组件:
1.1 顶层控制模块
- 意图澄清Agent:
- 采用规则模板+相似度匹配处理模糊问题,阈值(例如<0.8)触发澄清
- 结合用户画像和历史会话进行意图预测,准确率(例如>95%)才确认
- 使用主动问答策略收集缺失信息,如套餐类型、使用场景等
- 进行初步意图分类,支持查询、办理、咨询等类型
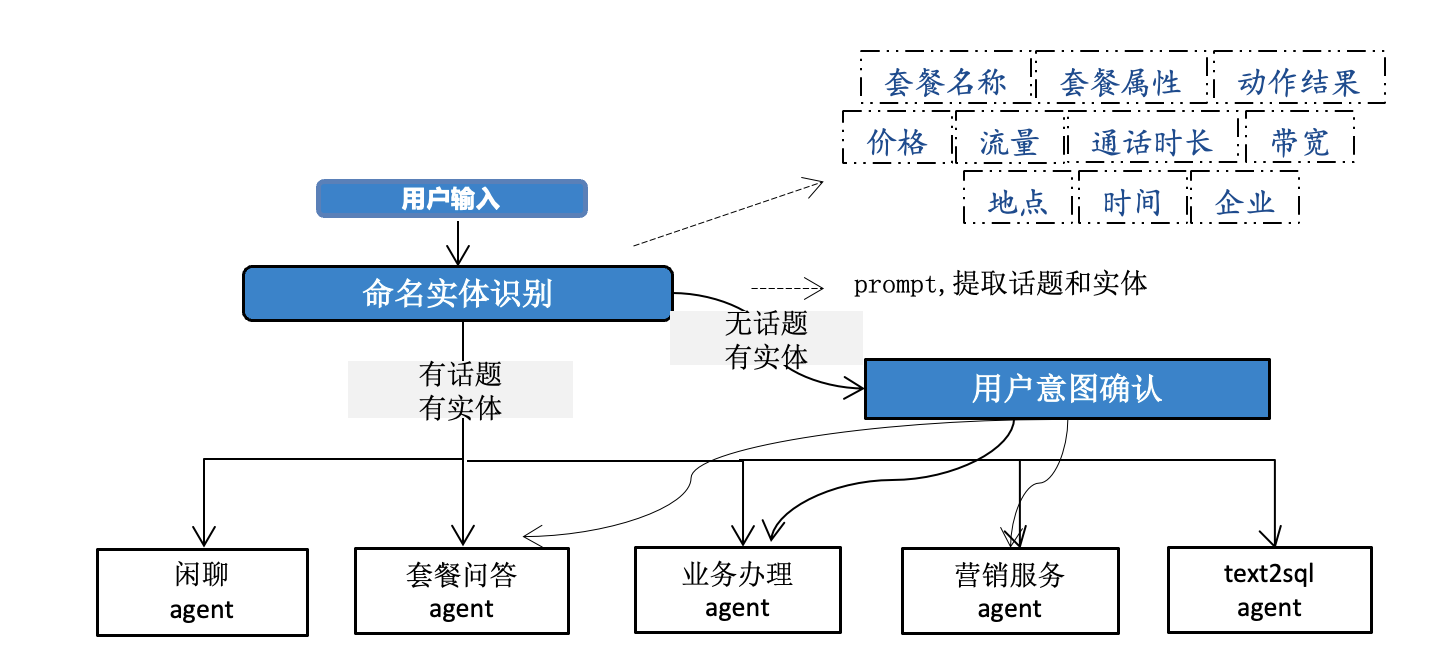
- 意图理解Agent:
- 使用NER(命名实体识别)技术识别业务实体(套餐名称、手机号码、时间等)
- 基于预定义规则模板进行意图匹配和分类
- 结合实体识别和规则匹配结果进行综合分析
- 输出标准化的意图理解结果(实体、类型、置信度)
- 任务规划Agent:
- 基于DAG图构建任务执行流程,将复杂任务拆解为原子任务节点
- 使用优先级队列管理任务调度,支持动态调整执行顺序
- 采用状态机管理任务生命周期,包含待执行、执行中、完成、失败等状态
- 通过发布-订阅模式实现任务间的解耦和异步通信
- 内置任务重试和异常处理机制,确保任务执行的可靠性
1.2 业务执行模块
系统根据不同业务场景划分为多个并行的业务处理单元,每个单元包含两层智能体:
- 意图识别Agent:
- 基于澄清结果精确识别用户意图
- 基于上下文和历史交互智能推断用户真实意图
- 处理badcase优化沉淀,持续提升意图识别准确率
- 适配多个助手的意图识别,实现精准分发
- 支持多维度意图识别,包括业务类型、查询范围、操作对象等
- 业务逻辑Agent:
- 执行具体的业务操作:处理用户查询、执行业务办理、提供智能推荐
- 负责与底层服务交互:调用业务接口、访问数据库、对接第三方系统
- 处理业务规则校验:权限验证、规则约束、异常处理
- 提供数据分析能力:数据统计、行为分析、性能监控
1.3 业务场景划分
系统支持多个并行的业务处理单元:
- 业务知识问答
- 问查算比
- 我的集团
- 其他助手服务
智能体框架
🛠️ 二、智能体框架选型
💡 框架选择关系到整个项目的成败,我们进行了深入的调研和分析。
2.1 调研方法与过程
🔍 如何选择最适合的框架?我们的调研过程是这样的:
关于调研方法和过程 我认为在评估智能体框架时,我们应该采取更加务实的调研方式。我们首先对市面上常见的智能体框架做了全面摸底,重点看了各个框架的使用情况、社区活跃度,以及实际落地案例。除此之外,我们也深入研究了每个框架的技术特点、性能表现和扩展能力,特别关注了它们的开发文档是否完善,技术栈是否能够很好地跟我们现有系统对接。
关于业务特点的思考 从我们移动业务的角度来看,我觉得有几个关键点特别重要:首先是要能扛住大流量,其次是要能适应我们多样化的业务场景,最后是要保证稳定性和安全性。这些业务特点决定了我们不能随便选择框架,而是需要一个既能保证性能,又足够灵活的解决方案。我们特别看重框架是否能够很好地处理复杂的对话流程,是否支持多轮对话,以及意图识别的准确度如何。
2.2 业务特点分析
🎯 从移动业务的特点出发,我们重点关注以下几个方面:
为什么最终选择了AutoGen 经过反复比较和讨论,我们觉得AutoGen是最适合我们的选择。说实话,这个决定并不是一蹴而就的。AutoGen吸引我们的地方主要有:它的API设计特别灵活,工具链也很完善,这对我们快速开发业务很有帮助;而且它支持多种编程语言,插件机制也很强大,这让我们能够根据实际需求进行定制开发;另外,有微软在背后支持,我们觉得框架的未来发展也更有保障。
具体实施的一些想法 为了落地AutoGen框架,我建议采取如下方案:
先以独立智能体的形式,将AutoGen模块以独立智能体的形式单独接入到现有的数智助手中。这种低成本验证能让我们在真实场景下迅速捕捉其表现和资源需求,及时发现问题。团队内部先进行一段试测,通过详细记录运行数据和用户反馈评估效果,再决定如何将该模块无缝融入整体业务框架中。
| 框架名称 | 框架描述 | 优缺点 |
|---|---|---|
| Qwen-Agent | 通义千问开源的智能体框架,提供了一套完整的智能体开发工具链 GitHub | 优点: • 基于Qwen大语言模型,中文理解能力强 • 提供丰富的工具调用能力,支持多种任务类型 • 支持多轮对话和任务规划 • 代码简洁易用,上手门槛低 • 提供完整的开发文档和示例 缺点: • 框架相对较新,生态还在建设中 • 目前主要支持Python语言 • 对Qwen模型依赖较强 • 社区规模相对较小 |
| AutoGPT | 一个自动化的GPT任务执行框架,能够自主完成复杂任务链 GitHub | 优点: • 自动化任务执行能力强 • 任务链扩展性好,可以处理复杂任务序列 • 社区活跃度高,更新迭代快 • 支持多种API集成 缺点: • 对计算资源要求较高 • 实验性质较强,生产环境稳定性待验证 • 配置过程相对复杂 |
| AgentGPT | 一个基于Web界面的多智能体协作框架,支持多个智能体协同工作 GitHub | 优点: • 多代理协同工作机制完善 • 界面友好,易于交互和操作 • 部署简单,上手快 • 支持自定义工作流 缺点: • 技术文档相对欠缺 • 系统稳定性需要进一步验证 • 功能扩展性有限 |
| LangChain Agents | 一个模块化的大语言模型应用开发框架,提供了丰富的智能体工具和组件 GitHub | 优点: • 高度模块化设计,组件丰富 • 框架灵活性强,可定制性高 • 生态系统完善,工具链齐全 • 社区支持度高,案例丰富 缺点: • 初始配置和设置较为复杂 • 学习曲线较陡峭 • 版本更新频繁,需要持续适配 |
| BabyAGI | 一个轻量级的自主智能体框架,适合入门学习和简单应用场景 GitHub | 优点: • 框架轻量,资源占用少 • 实现简单,代码易懂 • 入门门槛低,适合学习 • 部署维护成本低 缺点: • 功能相对基础,复杂场景支持有限 • 企业级应用适用性不高 • 缺乏高级特性支持 |
| AutoGen | 微软开源的新一代智能体框架,支持多语言开发,提供完整的开发工具链 GitHub | 优点: • 多层次API设计,满足不同开发需求 • 强大的插件扩展系统 • 优秀的跨语言支持(特别是.NET与Python) • 内置工具链丰富完善 • 微软官方支持,社区活跃 • 持续更新维护,版本稳定 缺点: • 初始学习成本较高 • 对最新技术栈依赖度高 • 系统资源要求较高 • 部分高级功能文档不够详细 |
🧠 三、Deepseek R1 融合
为了进一步提升系统的语义理解和意图解析能力,我们计划引入最新的 Deepseek R1 模型,并将其与现有的多智能体架构深度融合。Deepseek R1 模型在深层语义分析、实体识别和复杂意图解析方面具有显著优势,为整体系统提供额外的智能支撑。
5.1 集成方案一:基于深度思考过程的认知迭代
在原有意图澄清与理解模块的基础上,我们进一步提取 Deepseek R1 模型内部的思考过程(chain-of-thought),并在此过程中调用知识库进行信息补充与反馈,使模型能通过多轮迭代不断优化解析结果。
整体流程如下:
- 初步解析与思考:调用 Deepseek R1 模型进行初步语义解析,并提取模型内部生成的思考过程(包含临时推理步骤、归纳信息等)。
- 知识库查询:利用初步生成的思考过程作为查询条件,获取相关的背景知识和数据补充。
- 融合与迭代优化:将知识库返回的信息与原始思考过程进行融合,作为下一轮输入,经过多轮迭代逐步收敛,直至输出稳定结果。
示例代码:
def deepseek_iterative_analysis(user_input, max_iterations=3):
# 第一步:调用 Deepseek R1 生成初步解析结果和内部思考过程
initial_result = deepseek_r1_api(user_input, mode="chain-of-thought")
# initial_result 示例格式:
# {"result": "初步解析结果", "chain_of_thought": "初步思考过程"}
combined_input = initial_result["chain_of_thought"]
for i in range(max_iterations):
# 1. 主动查询知识库获取相关信息
kb_info = query_knowledge_base(combined_input)
# 2. 让知识库根据当前思考状态推送补充信息
kb_suggestions = knowledge_base_suggestions(combined_input)
# 3. 合并两种知识来源
enriched_knowledge = merge_knowledge(kb_info, kb_suggestions)
# 将知识库信息与当前思考内容组合,形成用于优化的新输入
input_for_refinement = {
"thought_process": combined_input,
"kb_query_results": kb_info,
"kb_suggestions": kb_suggestions,
"context": enriched_knowledge
}
# 迭代优化:调用 Deepseek R1 进行进一步解析
refined_result = deepseek_r1_api(input_for_refinement, mode="iterative-refinement")
# 4. 更新知识库
update_knowledge_base(refined_result)
# 更新思考过程
combined_input = refined_result.get("chain_of_thought", combined_input)
# 根据一定收敛指标判断是否提前退出迭代
if has_converged(combined_input):
break
final_result = {
"final_intent": refined_result.get("result", initial_result["result"]),
"final_chain_of_thought": combined_input
}
return final_result
# 辅助函数(伪代码实现)
def query_knowledge_base(query_text):
"""
主动查询知识库获取信息
"""
return {
"query_results": "查询到的知识",
"confidence": 0.85,
"source": "knowledge_base"
}
def knowledge_base_suggestions(thought_process):
"""
知识库根据当前思考过程主动推送相关信息
"""
return {
"suggestions": "知识库推荐的补充信息",
"relevance": 0.75,
"reasoning": "推荐原因"
}
def merge_knowledge(kb_info, kb_suggestions):
"""
合并主动查询和被动推送的知识
"""
return {
"combined_knowledge": "整合后的知识",
"priority": "优先级排序",
"metadata": {
"query_source": kb_info,
"suggestion_source": kb_suggestions
}
}
def update_knowledge_base(refined_result):
"""
根据推理结果更新知识库
"""
# 实现知识库的动态更新逻辑
pass
def has_converged(chain_text):
"""
判定收敛条件:例如检测思考过程变化是否小于预设阈值
"""
return len(chain_text) < 100 or "converged" in chain_text
上述代码展示了如何通过多轮迭代,将 Deepseek R1 的内部思考过程与外部知识库数据相结合,以实现逐步优化的语义解析。
以下是一个移动业务场景的实际应用案例:
场景案例:套餐推荐优化
🔍 用户咨询:”我想给父母换个套餐,他们每月通话时长200分钟左右,偶尔刷视频,主要是和家人视频通话,预算150元以内。”
| 传统向量检索模式 | Deepseek R1 思维链模式 |
|---|---|
|
处理流程: 1. 提取关键词: "通话时长200分钟", "视频通话", "150元" 2. 向量检索匹配相似套餐 3. 按相似度排序推荐 存在问题: • 缺乏场景理解,可能推荐不合适套餐 • 无法理解"父母"这类用户特征 • 忽略了"偶尔刷视频"的频率特征 • 推荐结果过于机械 |
思维链分析: 1. 用户画像解析 ✓ 目标用户:老年群体(父母) ✓ 使用习惯:以通话为主,视频使用频率低 ✓ 消费特征:预算敏感,性价比导向 2. 需求分层 ✓ 核心需求:通话套餐(约200分钟) ✓ 次要需求:视频通话流量 ✓ 价格上限:150元 3. 套餐匹配逻辑 ✓ 优先考虑老年专属套餐 ✓ 通话时长满足200分钟基本需求 ✓ 适量流量满足视频通话需求 ✓ 套餐价格需预留一定余量 4. 个性化建议 ✓ 推荐开通亲情网 ✓ 建议设置流量提醒 ✓ 介绍相关优惠活动 |
|
推荐结果: 直接推荐"月租129元200分钟通话+10G流量套餐" |
智能推荐: 1. 主套餐:老年关爱套餐 118元/月 - 300分钟通话 - 5G定向流量(视频通话专用) - 送亲情网业务 2. 备选方案:夕阳红套餐 108元/月 - 200分钟通话 - 3G定向流量 - 赠送视频通话特权 |
5.2 集成方案二:新增独立 Deepseek R1 Agent
为了更灵活地利用 Deepseek R1 的能力,可以将其封装为一个独立的智能体,作为整个多智能体协作系统中的一员。其他 Agent 在遇到复杂语义问题时,可主动调用此 Deepseek Agent 获取更精细的解析结果。
示例代码:
import requests
class DeepseekAgent:
def __init__(self, api_token):
self.api_token = api_token
self.endpoint = "https://api.deepseekr1.com/analyze"
def analyze(self, user_input):
payload = {"input": user_input}
headers = {"Authorization": f"Bearer {self.api_token}"}
response = requests.post(self.endpoint, json=payload, headers=headers)
if response.status_code == 200:
return response.json()
else:
return {}
# 示例:在多智能体系统中调用 DeepseekAgent
def process_with_deepseek_agent(user_input):
deepseek_agent = DeepseekAgent(api_token="YOUR_API_TOKEN")
result = deepseek_agent.analyze(user_input)
return result
5.3 融合优势与效果展望
- 准确性提升:深层语义解析有助于显著提高意图和实体识别的准确率,降低错误理解的概率。
- 决策支持:融合后的解析结果可为任务规划和后续处理提供更可靠的语义信息,优化决策流程。
- 模块灵活性:无论是作为现有 Agent 的增强,还是独立智能体存在,Deepseek R1 模型均可以根据业务需求灵活调度和升级。
未来,我们将持续监控 Deepseek R1 模型在实际场景下的表现,并根据用户反馈不断优化融合策略,确保系统在智能化水平上保持领先。
📅 四、一季度开发计划
一季度研发排期(基于多智能体的意图识别优化)
| 阶段 | 工作任务 | 描述 | 目标 | 进展 | 计划完成时间 |
|---|---|---|---|---|---|
| 1阶段 (1月20 ~ 2月10) |
AutoGen框架调研 | 深入研究AutoGen框架特性,评估业务适配性,完善技术架构设计 | 输出AutoGen框架评估报告和详细的技术方案设计文档 | 进行中 | 2025年2月6日 |
| 基础环境搭建 | 搭建AutoGen开发环境,完成基础组件配置,建立标准化开发规范 | 完成AutoGen基础环境搭建和开发规范制定 | 待开发 | 2025年2月10日 | |
| 2阶段 (2月11 ~ 3月5) |
独立模块接入 | 将AutoGen智能体作为独立模块接入现有数智助手系统 | 完成AutoGen模块的独立接入和基础功能验证 | 待开发 | 2025年2月20日 |
| 小规模试点 | 在特定业务场景下进行小规模试点测试,收集运行数据 | 完成试点测试并达到90%的意图识别准确率 | 待开发 | 2025年2月25日 | |
| 性能优化 | 基于试点数据优化智能体性能,调整资源配置 | 优化系统性能,实现75%的业务场景覆盖 | 待开发 | 2025年3月5日 | |
| 3阶段 (3月6 ~ 3月21日) |
意图澄清能力开发 | 开发基于AutoGen的意图澄清功能,提升多轮对话准确性 | 实现初步的意图澄清能力,提升用户体验 | 待开发 | 2025年3月12日 |
| 系统测试 | 进行全面的功能测试和性能测试,验证系统稳定性 | 完成系统测试,确保各项指标达标 | 待开发 | 2025年3月17日 | |
| 效果评估 | 收集并分析运行数据,评估优化效果,输出评估报告 | 完成第一季度效果评估报告,为下阶段优化提供依据 | 待开发 | 2025年3月21日 |
🎯 五、全年建设计划
| 季度 | 主要目标 | 关键措施 | 原有成果 vs 优化后成果 |
|---|---|---|---|
| 第一季度 | 基于AutoGen多智能体框架的意图理解增强 |
1. 以独立模块形式接入AutoGen智能体 2. 在现有数智助手中进行小规模试点 3. 收集运行数据与用户反馈 4. 优化智能体性能与资源占用 5. 评估业务场景适配性 |
【原有效果】 • 意图识别准确率:80% • 业务场景覆盖:60% 【优化后效果】 • 意图识别准确率:90% • 业务场景覆盖:75% • AutoGen模块接入验证 • 初步意图澄清能力 |
| 第二季度 | Deepseek R1融合与智能体全面整合 |
6. AutoGen智能体全面整合到业务框架 7. 引入Deepseek R1模型,实现chain-of-thought推理 8. 构建完整的多智能体协作机制 9. 实现基于DAG的任务规划系统 10. 开发智能体能力画像系统 |
【原有效果】 • 任务响应时间:300ms • 调度成功率:85% • 并发处理能力:1000 QPS 【优化后效果】 • 任务响应时间:150ms • 调度成功率:95% • 并发处理能力:3000 QPS • 支持动态任务优先级 • 智能体协作效率提升40% |
| 第三季度 | 知识图谱与安全体系建设 |
11. 构建动态加密知识图谱 12. 实现数据分级加密机制 13. 开发智能脱敏系统 14. 建立安全审计追踪 15. 优化数据访问控制 |
【原有效果】 • 安全评分:70分 • 数据加密覆盖:60% • 安全事件响应:4h 【优化后效果】 • 安全评分:90分 • 数据加密覆盖:95% • 安全事件响应:30min • 漏洞数量减少50% • 支持全链路追踪 |
| 第四季度 | 智能体决策优化与协作升级 |
16. 构建规约化能力画像体系 17. 实现多智能体选举投票机制 18. 优化智能体协作架构 19. 落地MMCP多模态上下文协议 20. 完善智能体评估与反馈体系 |
【原有效果】 • 智能体匹配率:75% • 任务响应时间:30分钟 • 数据传输效率:基准值 【优化后效果】 • 智能体匹配率:95%以上 • 任务响应时间:15分钟 • 数据压缩比:60% • 调用时间缩短60% • 单智能体效率提升2倍 |
</div>